在数据采集的世界里,HTTP代理扮演着至关重要的角色。它们不仅帮助我们访问全球的数据资源,还提高了数据采集的效率和质量。但面对市场上众多的HTTP代理服务,我们该如何选择最适合自己的那一个呢?本文将为你提供一些实用的建议和指导,帮助你在数据采集的道路上更加得心应手。 ## 了解HTTP代理的基本原理 在深入探讨如何选择HTTP代理之前,我们先来简单了解一下HTTP代理的基本原理。HTTP代理服务器作为客户端和目标服务器之间的中介,可以接收客户端的请求并转发到目标服务器,然后再将服务器的响应返回给客户端。这种机制使得数据采集者可以利用代理服务器来访问互联网资源,同时保持请求的连续性和稳定性。 ## 如何选择适合自己的HTTP代理 选择适合自己的HTTP代理,需要考虑以下几个关键因素: ### 1. 速度与稳定性 速度和稳定性是选择HTTP代理时的首要考虑因素。一个快速且稳定的代理可以确保数据采集的连续性和效率。在选择代理服务时,可以查看服务提供商的承诺速度和用户反馈,甚至可以先试用服务,亲自测试其性能。 ### 2. IP地址的覆盖范围 数据采集往往需要访问全球范围内的网站,因此,选择一个拥有广泛IP地址覆盖的代理服务是非常重要的。这样,你可以根据不同的地区需求,选择合适的IP地址进行数据采集。 ### 3. 定制化服务 不同的数据采集项目可能需要不同的代理配置。选择能够提供定制化服务的代理提供商,可以满足特定项目的需求,如特定的IP地址、特定的带宽等。 ### 4. 价格与成本效益 价格是选择HTTP代理时需要考虑的实际因素。不同的代理服务提供不同的价格方案,从免费到付费不等。在选择时,要权衡价格和服务质量,找到最适合自己的成本效益平衡点。 ### 5. 客户支持和服务 良好的客户支持和服务也是选择HTTP代理时需要考虑的因素。当你遇到问题时,一个响应迅速、服务周到的客户支持团队可以为你节省大量的时间和麻烦。 ## 实践中的选择策略 在实际选择HTTP代理时,可以采取以下策略: ### 1. 明确需求 在开始选择之前,先明确你的数据采集需求,包括需要访问的网站类型、地区、数据量等,这将帮助你更有针对性地选择代理服务。 ### 2. 比较服务提供商 市场上有许多HTTP代理服务提供商,你可以比较他们的服务特点、价格、用户评价等,找到最符合你需求的服务。 ### 3. 试用服务 许多代理服务提供商都提供试用期或免费套餐,你可以利用这些机会试用服务,亲自体验其性能和服务质量。 ### 4. 监控和调整 在数据采集过程中,持续监控代理的性能,并根据需要进行调整。如果发现某个代理服务不再满足你的需求,不要犹豫,及时更换。 ## 结语 选择适合自己的HTTP代理是一个需要综合考虑多个因素的过程。通过本文的介绍,希望你能对如何选择HTTP代理有一个清晰的认识,并在实际的数据采集工作中,找到最适合自己的代理服务。记住,一个好的HTTP代理可以大大提高你的数据采集效率和质量,是数据采集工作中不可或缺的伙伴。
按win+r快捷键,打开运行窗口,输入`taskschd.msc` 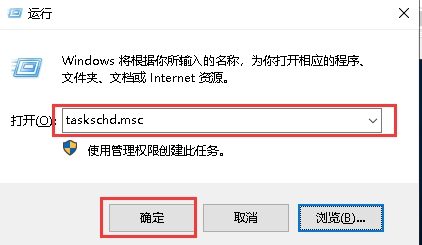 打开计划任务窗口,左侧点击“任务计划程序库”,右侧点击“导入任务” 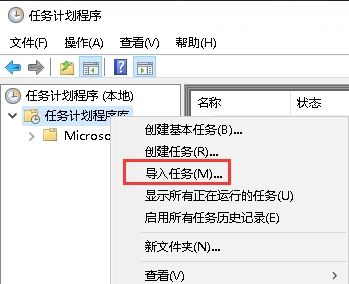 在弹出对话框选择需要导入的计划任务xml文件 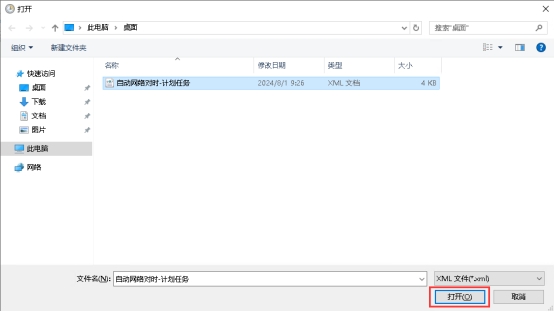 在弹出的对话框中,点击“确定”即可导入 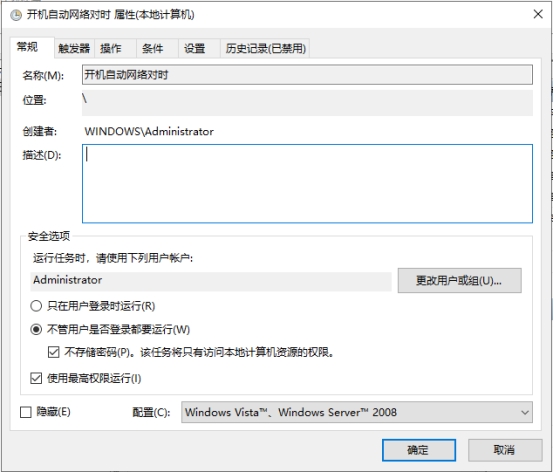
在运行处输入`services.msc`打开服务控制台,找到"windows time"服务设置为手动并启动即可 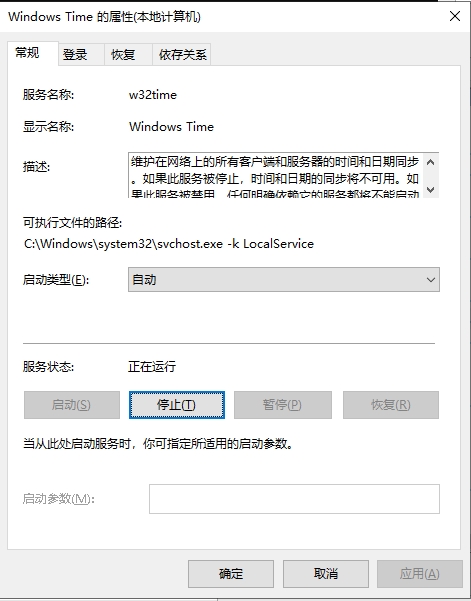 进入系统设置,找到【日期和时间】,打开【自动设置时间】和【自动设置时区】 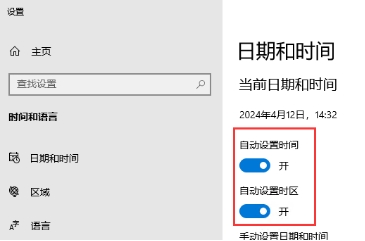 计划任务设置开机自动对时 添加计划任务:win+r快捷键打开运行窗口,输入`taskschd.msc`打开计划任务窗口,左侧点击“任务计划程序库”,右侧点击“创建任务” 安全选项:选择“不管用户是否登录都要运行(W)”并勾选“不存储密码(P)…”和“使用最高权限运行(I)”。如下图所示 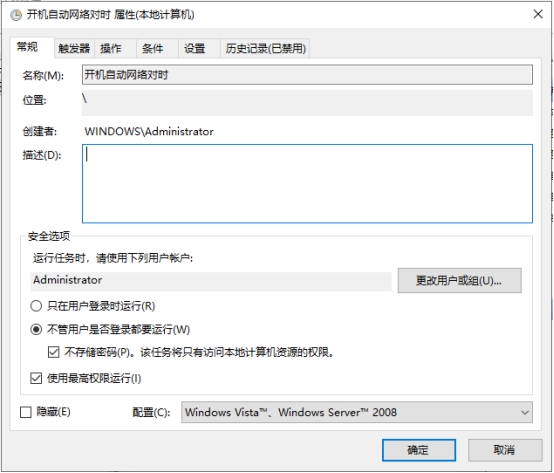 切换到“触发器”选项卡。点击下方“新建”按钮。开始任务选择“启动时”,高级设置勾选“延迟任务时间”并设置10秒。(此配置是等待网络连接,无网络连接则时间同步会失败) 勾选“重复任务间隔”并设置1小时,持续时间:无限制 勾选“已启用” 配置完后点击“确定”按钮,如下图所示: 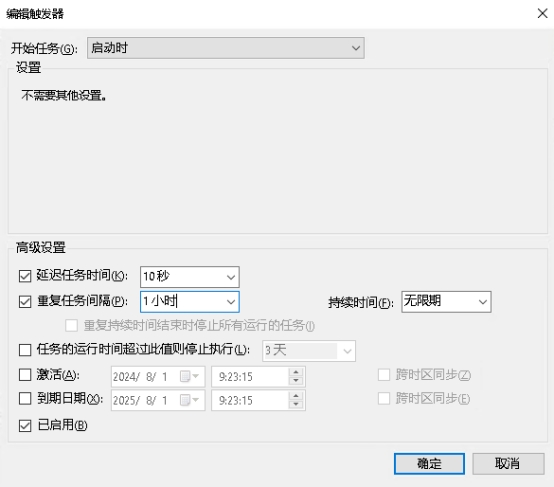 切换到“操作”选项卡,点击下方的“新建”按钮,操作默认为“启动程序” 开启Windows Time服务 程序或脚本(P)填入 %windir%\system32\cmd.exe 添加参数(可选)填入 /k net start w32time 执行网络对时 程序或脚本(P)填入 %windir%\system32\cmd.exe 添加参数(可选)填入 /k w32tm /config /update /manualpeerlist:time.windows.com 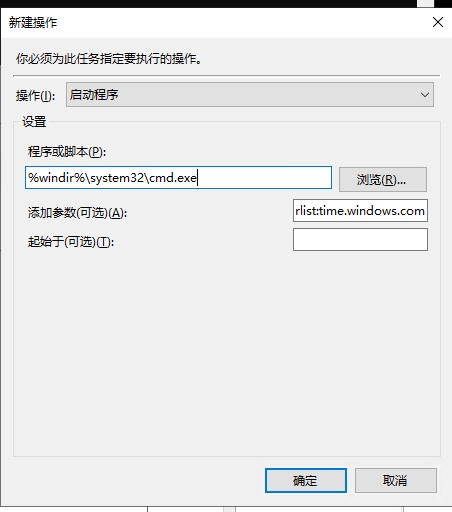 切换到“条件”选项卡,下方“网络”处,勾选“只有在以下网络连接可用时才启动(Y)”。并选择实际的网络。该网络必须是时间服务器所使用的网络。(因为上面设置了延迟30秒启动,如过能保证网络在30秒内正常启动。则此项可忽略)。 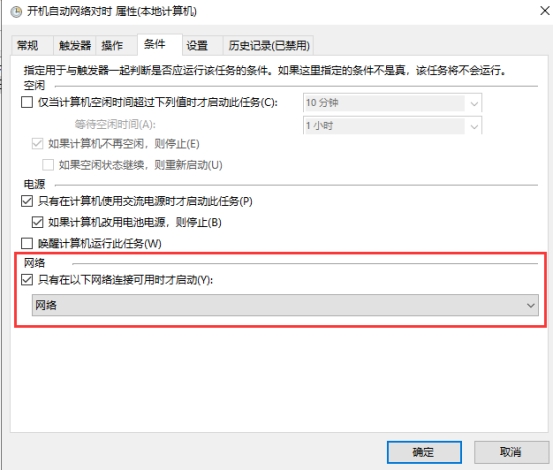 切换到“设置”选项卡,勾选“如果过了计划开始时间,立即启动任务”和“如果任务失败,按以下频率重新启动”,其他保持默认。 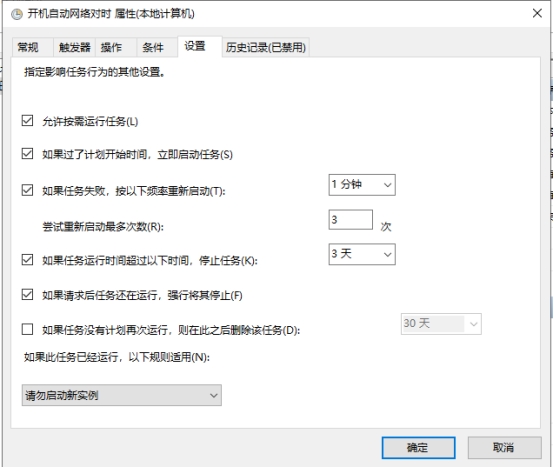 点击确定按钮,此时添加了一条计划任务。每次启动或重启系统后,会自动同步一次时间。
一、for循环语句
当面对各种列表重复任务时,使用简单的if语句已经难以满足要求,而顺序编写全部代码更是显得异常繁琐,困难重重。这将可以使用for循环语句很好的解决类似问题。
1、for语句的结构
使用for循环语句时,需要指定一个变量及可能的取值列表,针对每个不同的取值重复执行相同的命令序列,直到变量值用完退出循环。在这里,“取值列表”称为for语句的执行条件,其中包括多个属性相同的对象,需要预先指定(如通讯录)。
for循环语句的语法结构如下所示:
for 变量名 in 取值列表
do
命令序列
done
上述语句结构中,for语句的操作对象为用户指定名称的变量,并通过in关键字为该变量预先设置了一个取值列表,多个取值之间以空格进行分隔。位于do...done之间的命令序列称为循环体,其中的执行语句需要引用变量以完成相应的任务。
2、for语句的执行流程
首先将列表中的第一个取值赋给变量,并执行do...done循环体中的命令序列;然后将列表中的第二个取值赋给变量,并执行循环体中的命令序列......依此类推,直到列表中的所有取值用完,最后将
跳至done语句,表示结束循环,如下图所示:

3、for语句应用示例
1)根据姓名列表批量添加用户
根据公司人事部门给出的员工姓名的拼音列表,在Linux服务器中添加相应的用户账户,初始密码均设置为“pwd@123”。其中,员工姓名列表中的账号数量并不固定,而且除了要求账号名称是拼音之外,并无其他特殊规律。
针对上述要求,可先指定员工列表文件user.txt,然后编写一个名为useradd.sh的shell脚本,从user.txt文件中读取各用户名称,重复执行添加用户,设置初始密码的相关操作。
vim user.txt <!--用做测试的列表文件-->
zhangsan
lisi
wangwu
Zhaoliu
vim useradd.sh <!--批量添加用户的脚本-->
#!/bin/bash
user=$(cat /root/user.txt)
for username in $user
do
useradd $username
echo "pwd@123" | passwd --stdin $username &> /dev/null
done
chmod x useradd.sh <!--添加执行权限-->
./useradd.sh <!--运行批量创建用户脚本-->
<!--确认执行结果-->

若要删除useradd.sh脚本所添加的用户,只需要参考上述脚本代码,将for循环体中添加用户的命令序列改为删除用户的操作即可。
vim deluser.sh <!--批量删除用户的脚本-->
#!/bin/bash
user=$(cat /root/user.txt)
for username in $user
do
userdel -r $username
done
chmod x deluser.sh <!--脚本文件添加执行权限-->
./deluser.sh <!--运行批量删除用户脚本-->
tail -5 /etc/passwd <!--查看执行结果-->

二、使用while循环语句
for循环语句非常适用于列表对象无规律,且列表来源已固定(如某个列表文件)的场合。而对于要求控制循环次数、操作对象按数字顺序编号、按特定条件执行重复操作等情况,则更适合适用另一种循环——while语句。
1、whie语句的结构
适用while循环语句时,可以根据特定的条件反复执行一个命令序列,直到该条件不再满足时为止。在脚本应用中,应该避免出现死循环的情况,否则后边的命令操作将无法执行。因此,循环体内的命令序列中应包括修改测试条件的语句,以便在适当的时候测试条件不再成立,从而结束循环。
while循环语句的语法结构如下所示:
while 条件测试操作
do
命令序列
done
2、while语句的执行流程
首先判断while后的条件测试操作结果,如果条件成立,则执行do...done循环体中的命令序列;返回while后再次判断条件测试结果,如果条件仍然成立,则继续执行循环体,再次返回到while后,判断条件测试结果.....如此循环,直到while后的条件测试结果不再成立为止,最后跳转到done语句,表示结束循环。如下图所示:

使用while循环语句时,有两个特殊的条件测试操作,即true(真)和false(假)。使用true作为条件时,表示条件永远成立,循环体内的命令序列将无限执行下去,除非强制终止脚本(或通过exit语句退出脚本);反之,若使用false作为条件,则循环体将不会被执行。这两个特殊条件也可以用在if语句的条件测试中。
3、while语句应用示例
1)批量添加规律编号的用户
在一些技术培训和学习领域,出于实验或测试的目的,需要批量添加用户账号,这些用户的名称中包含固定的前缀字串,并按照数字顺序依次进行编号,账号的数量往往也是固定的。
vim useraddress.sh <!--批量添加用户的脚本-->
#!/bin/bash
prefix="user"
i=1
while [ $i -le 20 ]
do
useradd ${prefix}$i
echo "pwd@123" | passwd --stdin ${prefix}$i &> /dev/null
let i
done
chmod x useraddress.sh <!--脚本添加执行权限-->
./useraddress.sh <!--运行脚本-->
grep "user" /etc/passwd | tail -20 <!--查看执行结果-->
上述脚本代码中,使用变量i来控制用户名称的编号,初始赋值为1,并且当取值大于20时终止循环。在循环体内部,通过语句“let i ”(等同于i= 'expr $i 1')来使用变量i的值增加1,因此当执行第一次循环后i的值将变为2,执行第二次循环后i的值将变为3,......,依此类推。
若要删除useraddress.sh ji脚本所添加的用户,只需参考上述脚本代码,将while循环体中添加用户的命令序列改为删除用户的操作即可。
[root@centos01 ~]# vim deluseraddress.sh <!--批量删除用户的脚本-->
#!/bin/bash
prefix="user"
i=1
while [ $i -le 20 ]
do
userdel -r ${prefix}$i
let i
done
chmod x deluseraddress.sh <!--脚本添加执行权限-->
./deluseraddress.sh <!--运行脚本-->
id user20 <!--确认执行结果-->

三、使用case分支语句
1、case语句的结构
case语句主要适用于以下情况:某个变量存在多种取值,需要对其中的每一种取值分别执行不同的命令序列。这种情况与分支的if语句非常相似,只不过if语句需要判断多个不同的条件,而case语句只是判断一个变量的不同取值。case分支语句的语法结构如下所示:
case 变量值 in
模式1)
命令序列1
;;
模式2)
命令序列2
;;
......
*)
默认命令序列
esac
在上述语句结构中,关键字case后面跟的是“变量值”,即“$变量名”,这点需要与for循环语句的结构加以区别。整个分支结构包括在case...esac之间,中间的模式1、模式2、......、对应为变量的不同取值(程序期望的取值),其中作为通配符,可匹配任意值。
2、case语句的执行流程
首先使用“变量值”与模式1进行比较,若取值相同则执行模式1后的命令序列,直到遇见双分号“;;”后跳转至esac,表示结束分支;若与模式1不相匹配,则继续与模式2进行比较,若取值相同则执行模式2后的命令序列,直到遇见双分号“;;”后跳转至esac,表示结束分支......依此类推,若找不到任何匹配的值,则执行默认模式“*)”后的命令序列,直到遇见esac后结束分支。如下图所示:

使用case分支语句时,有几个值得注意的特点如下所述:
case行尾必须为单词“in”,每一模式必须以右括号“)”结束。
双分号“;;”表示命令序列的结束。
模式字符串中,可以用方括号表示一个连续的范围,如“[0-9]”;还可以用竖杠符号“|”表示或。
最后的“)”表示默认模式,其中的相当于通配符。
3、case语句应用示例
1)检查用户输入的字符类型
提示用户从键盘输入一个字符,通过case语句判断该字符是否为字母,数字或者其他控制字符,并给出相应��提示信息。
vim hitkey.sh <!--创建编写检查用户输入的字符类型-->
#!/bin/bash
read -p "请输入一个字符,并按Enter键确认:" KEY
case "$KEY" in
[a-z] | [A-Z]) <!--匹配任意字母-->
echo "您输入的是 字母."
;;
[0-9]) <!--匹配任意数字-->
echo "您输入的是 数字."
;;
*) <!--默认模式,匹配任何字符-->
echo "您输入的是 空格、功能键或其他控制字符."
esac
chmod x hitkey.sh <!--脚本添加执行权限 -->
./hitkey.sh <!--运行脚本并确认执行结果-->

单行注释:
单行注释就比较简单了,直接在行最前端加上符号 # 即可。具体用法如下所示:
# this is comment test
echo "this is comment test"运行结果:

多行注释:
多行注释有很多方法,这里就列举几个常用的
1 eof截止符
eof截止符不但可以用作后续输入命令,还可以用作注释,常用用法:开始注释部分:输入::<<eof 结束部分:eof
具体示例如下所示:
# echo is test
echo "test"
echo "test"
echo "test"
echo "test"
echo "test"
:<<eof
echo "comment"
echo "comment"
echo "comment"
echo "comment"
echo "comment"
echo "comment"
eof
运行结果:

2 感叹号
!号一般作为嵌入内容部分,可以用作注释,常用用法:开始注释部分:输入::<<! 结束部分:!
具体示例如下所示:
# echo is test
echo "test"
echo "test"
echo "test"
echo "test"
echo "test"
:<<!
echo "comment"
echo "comment"
echo "comment"
echo "comment"
echo "comment"
echo "comment"
!
运行结果:

3 逗号
逗号一般作区分内容,也可以用作注释,常用用法:开始注释部分:输入:: ' 结束部分:' (注意,逗号和冒号之间要加空格)
具体示例如下所示:
# echo is test
echo "test"
echo "test"
echo "test"
echo "test"
echo "test"
: '
echo "comment"
echo "comment"
echo "comment"
echo "comment"
echo "comment"
echo "comment"
'
运行结果:

一、条件测试操作
要使Shell脚本程序具备一定的“智能”,面临的第一个问题就是如何区分不同的情况以确定执行何种操作。Shell环境根据命令执行后的返回状态值(¥?)来判断是否执行成功,当返回值为0时表示成功,否则(非0值)表示失败或异常。使用专门的测试工具——test命令,可以对特定条件进行测试,并根据返回值来判断条件是否成立(返回值为0表示条件成立)。
使用test测试命令时,包括以下两种形式:
test 条件表达式
[ 条件表达式 ]
这两种方式的作用完全相同,但通常后一种形式更为常用,需要注意的是,方括号“[“ 或 ”]”与条件表达式之间需要至少一个空格进行分隔。
1、文件测试:
-d:测试是否为目录(Directory);
-e:测试文件或目录是否存在(Exist);
-f:测试是否为文件(File);
-r:测试当前用户是否有权限读取(Read);
-w:测试当前用户是否有权限写入(Write);
-x:测试是否设置有可执行(Excute)权限;
执行条件测试操作以后,通过预定义变量$?可以获得测试命令的返回状态值,从而判断该条件是否成立。例如,执行以下操作可以测试目录/media/是否存在,如果返回值$?为0,表示存在此目录,否则表示不存在或者虽然存在但不是目录。
![]()
若测试的条件不成立,则测试操作的返回值将不为0(通常为1).

2、整数值比较:
-eq:第一个数等于(Equal)第二个数;
-ne:第一个数不等于(Not Equal)第二个数;
-gt:第一个数大于(Greater Than)第二个数;
-lt:第一个数小于(Lesser Than)第二个数;
-le:第一个数小于或等于(Lesser or Equal)第二个数;
-ge:第一个数大于或等于(Greater or Equal)第二个数;
整数值比较在Shell脚本编写中的应用较多。例如,用来判断已登录用户数量、开启进程数、磁盘使用率是否超标,以及软件版本号是否符号要求等。实际 使用时,往往会通过变量引用、命令替换等方式来获取一个数值。
3、字符串比较:
=:第一个字符串与第二个字符串相同。
!=:第一个字符串与第二个字符串不相同,其中 “ !”表示取反。
-z:检查字符串是否为空,对于未定义或赋予空值的变量将是为空串。

<!--当1等于2显示yes,不等于显示为空-->
<!--显示为空-->

<!--当1不等于2显示yes,否则显示为空-->
yes <!--1不等于2,显示yes-->
4、逻辑测试:
&&:逻辑与,表示“而且”,只有当前后两个条件都成立时,整个测试命令的返回值才为0(结果成立),使用test命令测试时,“&&”可以使用“-a”代替。
||:逻辑或,表示“或者”,只要前后两个条件有一个成立,整个测试命令返回的值即为0(结果成立)。使用test命令测试时可以使用“-o”代替。
!:逻辑否,表示“不”,只有当条件不成立时,整个测试命令返回的值才为0(结果成立)。
示例如下:

<!--使用逻辑与运算,两个条件为真显示yes-->
yes <!--两个条件为真,显示yes-->

<!--使用逻辑与运算,两个条件一个为真显示为yes-->
yes <!--两个条件一个为真,显示yes-->
二、使用if条件语句
1、单分支if语句
if语句的“分支”指的是不同测试结果所对应的执行语句(一条或多条)。对于单分支的选择结构,只有在“条件成立”时才会执行相应的代码,否则不会执行任何操作。单分支if语句的语法格式如下所示:
单分支if语句示例:
![]()
vim if_dan.sh <!--编写创建/usr/src/ppp目录的脚本-->
#!/bin/bash <!--脚本声明-->
mount="/usr/src/ppp" <!--定义一个变量-->
if [ ! -d $mount ] <!--测试条件-->
then <!--如果满足则执行下面的命令-->
mkdir -p $mount
fi <!--if语句结束-->

2、双分支if语句
对于双分支的选择结构,要求针对“条件成立” “条件不成立”两种情况分别执行不同的操作。双分支if语句的语法格式如下所示:
双分支if语句示例:
vim if_shuang.sh <!--编写脚本测试网络连通性-->
#!/bin/bash
ping -c 3 -i 0.2 -W 3 $1 &> /dev/null <!--ping 3次,间隔0.2秒,超时3秒,$1为位置变量-->
if [ $? -eq 0 ] <!--测试条件为前一条的命令执行成功-->
then <!--如果成功,则执行以下命令-->
echo "Host:$1 is UP!!!"
else <!--若不成功,则执行以下命令-->
echo "Host:$1 is DOWN!!!"
fi <!--if语句结束-->


3、多分支if语句
由于if语句可以根据测试结果的成立、不成立分别执行操作,所有能够嵌套使用,进行多次判断。例如,首先判断某学生的得分是否及格,若及格则再次判断是否高于90分等。多分支if语句的语法格式如下:
多分支if语句示例:
[root@centos01 ~]# vim if_duo.sh <!--编写脚本测试学生成绩-->
#!/bin/bash
read -p "请输入考试成绩:" insert
if [ $insert -ge 85 ] && [ $insert -le 100 ] <!--85~100分,优秀-->
then
echo "恭喜您考试成绩为优秀!!!"
elif [ $insert -ge 70 ] && [ $insert -le 84 ] <!--70~84分,合格-->
then
echo "恭喜您考试成绩为合格!!!"
else <!--其他分数,不合格-->
echo "很遗憾您考试成绩可以收拾收拾回家种苞米了!!!"
fi <!--if语句结束-->

一、Shell脚本基础
Linux系统中的Shell脚本是一个特殊的应用程序,它介于操作系统内核与用户之间,充当了一个“命令解释器”的角色,负责接收用户输入的操作命令并进行解释,将需要执行的操作传递给内核执行,并输出执行结果。
1、简单编写Shell脚本
vim aaa.sh <!--新建aaa.sh文件-->

chmod x aaa.sh <!--添加可执行权限-->
上述aaa.sh脚本文件中,第一行“#!/bin/bash”是一行特殊的脚本声明,表示此行以后的语句通过/bin/bash程序来解释执行;其他以“#”开头的语句表示注释信息;echo命令用于输出字符串,以使脚本的输出信息更容易读懂。上述配置包括三条命令:cd /boot/、pwd、ls -lh vml*。执行此脚本文件后,输出结果与依次单独执行这三条命令是相同的,从而实现了“批量处理”的自动化过程。
通过“./aaa.sh”的方式执行脚本,执行之前必须授权于文件的X权限。
./aaa.sh <!--运行脚本文件-->

二、重定向与管道操作
1、重定向输出
表示将命令的正常输出结果保存到指定的文件中,并覆盖文件中的原有内容,若文件不存在,则会新建一个文件使用 “>”操作符号。
表示将命令的正常输出结果追加到指定的文件中sh使用“>>”操作符号。
举个例子:
echo "aaa" <!--数据输出到显示器上显示-->

echo "aaa" > 1.txt <!--将数据输出到文件中-->
cat 1.txt <!--查看文件中数据-->

echo "bbb" >> 1.txt <!--将数据追加输出到1.txt文件中-->
cat 1.txt <!--查看文件-->

2、重定向输入
重定向输入指的是将命令中接收输入的途径由默认的键盘改为指定的文件,而不是等待从键盘输入。重定向输入使用“<”操作符。
举个例子:
使用passwd命令为用户设置密码时,每次都必须根据提示输入两次密码字串,非常繁琐,若改用重定向输入将可以省略交互式的过程,而自动完成密码设置。
useradd bob <!--创建bob用户-->
vim password.txt <!--添加初始密码串-->
pwd@123 <!--密码为pwd@123-->
passwd --stdin bob < password.txt <!--从password.txt文件中取密码-->

shell脚本之信号的捕捉
trap,翻译过来就是陷阱的意思,shell脚本中的陷阱是专门用来捕捉信号的。啥信号呢?比如经常使用的kill -9,kill -15,CTRL C等都属于信号
1、查看所有可用的信号
trap -l或kill -l即可
kill -l
trap -l

2、常见的信号如下:
Signal Value Comment
─────────────────────────────
SIGHUP 1 终止进程,特别是终端退出时,此终端内的进程都将被终止
SIGINT 2 中断进程,几乎等同于sigterm,会尽可能的释放执行clean-up,释放资源,保存状态等(CTRL C)
SIGQUIT 3 从键盘发出杀死(终止)进程的信号
SIGKILL 9 强制杀死进程,该信号不可被捕捉和忽略,进程收到该信号后不会执行任何clean-up行为,所以资源不会释放,状态不会保存
SIGTERM 15 杀死(终止)进程,几乎等同于sigint信号,会尽可能的释放执行clean-up,释放资源,保存状态等
SIGSTOP 19 该信号是不可被捕捉和忽略的进程停止信息,收到信号后会进入stopped状态
SIGTSTP 20 该信号是可被忽略的进程停止信号(CTRL Z)
真正的信号名字不是SIGXXX,而是去除SIG后的单词,每个信号还有对应的代号
比如向PID为12345的进程发起1信号
kill -1 12345
kill -HUB 12345
kill -SIGHUB 12345
3、trap的选项
trap -l列出当前系统支持的信号列表,上面已经使用过,根kill -l一样
trap -p等价于trap,查看shell已经布置好的陷阱
可以看到shell默认有三个陷阱,表示忽略20,21,22信号
4、陷阱捕捉到信号后干嘛
•忽略信号
•捕捉到信号后做相应的处理。主要是清理一些脚本创建的临时文件,然后退出。
5、设置一个可以忽略CTRL C和15信号的陷阱
CTRL信号对应的是SIGINT 15信号对应的是SIGTERM
trap '' SIGINT SIGTERM
trap
这样,当前shell就不能被kill -15杀死
6、设置一个陷阱,捕捉到-15信号时,就打印“我抓到你啦~”
trap 'echo "我抓到你啦~"' TERM
trap 效果,当我对当前bash发起kill -15信号时就打印出来了
效果,当我对当前bash发起kill -15信号时就打印出来了

7、在脚本中设置一个能忽略CTRL C和CTRL Z信号的脚本
CTRL C是2信号,即SIGINT
CTRL Z是20信号,即SIGTSTP
脚本:
脚本沉睡10s,然后打印success,脚本忽略INT和TSTP信号
Vim trap.sh
#!/bin/bash
trap '' SIGINT SIGTSTP
sleep 10
echo success
效果:

8、布置一个当脚本被终端时能清理垃圾并立即退出脚本的陷阱
脚本如下:
Vim trap1.sh
#!/bin/bash
trap 'echo trap handing...;rm -rf /tmp/$BASHPID;echo TEMP files cleaned;exit' SIGINT SIGTERM SIGQUIT SIGHUP
mkdir -p /tmp/$$/
touch /tmp/$$/{a..c}.txt
sleep 10
echo first sleep success
sleep 10
echo second sleep success
这样,脚本除了SIGKILL信号(kill -9),总能清理掉临时垃圾
效果

9、陷阱的守护对象
陷阱的守护对象是shell进程本身,不会守护shell环境内的子进程。但如果是信号忽略型陷阱,则会守护整个shell进程组使其忽略给定信号。
Vim trap2.sh
#!/bin/bash
trap 'echo trap_handle_time: $(date "%F %T")' SIGINT SIGTERM
echo time_start: $(date "%F %T")
sleep 10
echo time_end1: $(date "%F %T")
sleep 10
echo time_end2: $(date "%F %T")
#执行脚本后,新开终端使用kill -15杀死它
[root@linux1 ~]# killall -s SIGTERM trap2.sh
#查看输出情况
./trap2.sh

可以发现,kill执行完后,屏幕没有立即打印trap_handle,而是等sleep 10运行完后才打印的。sleep进程都被忽略型trap守护了
只要是向shell进程发送的信号,都会等待当前正在运行的命令结束后才处理信号,然后继续脚本向下运行。(实际上,只有当shell脚本中正在执行的操作是信号安全的系统调用时,才会出现信号无法中断进程的情况,而在shell下的各种命令,我们是没法直接知道哪些命令中正在执行的系统调用是系统调用的)。
但sleep命令发起的sleep()调用,是一个信号安全的,所以上面脚本中执行sleep的过程中,信号不会直接中断它们的运行,而是等待它运行完之后再执行信号处理命令。
一、正则表达式的定义
正则表达式又称正规表达式、常规表达式。在代码中常简写为regex、regexp或RE。正则表达式是使用单个字符串来描述,匹配一系列符合某个句法规则的字符串,简单来说,是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串。
正则表达式是由普通字符与元字符组成的文字模式。模式用于描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。其中普通字符包括大小写字母、数字、标点符号及一些其他符号,元字符则是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
1、基础正则表达式
正则表达式的字符串表达方法根据不同的严谨程度与功能分为基本正则表达式与扩展正则表达式。基础正则表达式是常用的正则表达式的最基础的部分。在Linux系统中常见的文件处理工具中grep与sed支持基础正则表达式,而egrep与awk支持扩展正则表达式。
提前准备一个名为test.txt的测试文件,文件具体内容如下:
vim test.txt
he was short and fat.
He was wearing a blue polo shirt with black pants.
The home of Football on BBC Sport online.
the tongue is boneless but it breaks bones.12!
google is the best tools for search keyword.
The year ahead will test our political establishment to the limit.
PI=3.14148223023840-2382924893980--2383892948
a wood cross!
Actions speak louder than words
#wooood #
#woooood #
AxyzxyzxyzxyzxyzC
I bet this place is really spooky late at night!
Misfortunes never come alone/single.
I shouldn't have lett so tast.
1)基础正则表达式示例:
grep -n 'the' test.txt <!--查找特定字符,-n显示行号-->
 grep -in 'the' test.txt <!--查找特定字符,-in显示行号不区分大小写-->
grep -in 'the' test.txt <!--查找特定字符,-in显示行号不区分大小写-->

grep -vn 'the' test.txt <!--查找不包括特定字符的行,-vn选项实现-->

2)grep利用中括号“[]”来查找集合字符
grep -n 'sh[io]rt' test.txt <!--中括号来查找集合字符,
“[]”中无论有几个字符,都仅代表一个字符,
也就是说“[io]”表示匹配“i”或者“o”-->

grep -n 'oo' test.txt <!--查找重复单个字符-->

grep -n '[^w]oo' test.txt <!--查找“oo”前面不是“w”的字符串,
使用“[^]”选项实现-->

grep -n '[^a-z]oo' test.txt <!--查找“oo”前面不存在小写字母-->

grep -n '[0-9]' test.txt <!--查找包含数字的行-->

3)grep查找行首“^”与行尾字符“$”
grep -n '^the' test.txt <!--查找以“the”字符串为行首的行-->

grep -n '^[a-z]' test.txt <!--查找以小写字母为行首的行 -->

grep -n '^[A-Z]' test.txt <!--查找以大写字母为行首的行-->

grep -n '^[^a-zA-Z]' test.txt <!--查找不以字母开头的行-->

grep -n 'w..d' test.txt <!--查找任意一个字符“.”与重复字符“*”-->

grep -n 'ooo*' test.txt <!--查看包含至少两个o以上的字符串-->

grep -n 'woo*d' test.txt <!--查询w开头d结尾,中间至少包含一个o的字符串-->

grep -n '[0-9][0-9]*' test.txt <!--查询任意数字所在行-->

grep -n 'o\{2\}' test.txt <!--查找连续两个o的字符“{}”-->

检查机器带宽是否跑满 1.打开“管理工具”找到“性能监视器”,然后双击打开。  2.先点击“监视工具”然后点击“性能监视器”,再点击右边的“添加符号”。 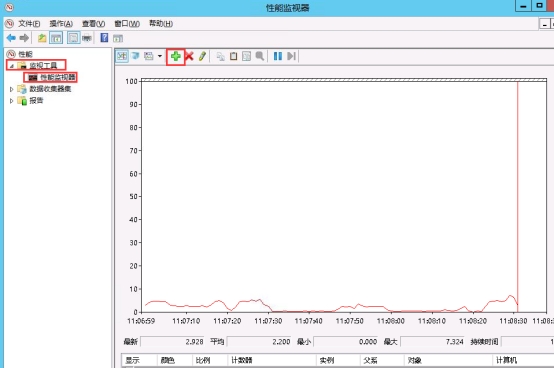 3.先找到“Hyper-V Virtual Network Adapter”然后选择“Bytes Received/sec”跟“Bytes Sent/sec”,然后在“选择对象的实例”里面找到需要查看的机器,选择网卡是“Bridge”的那个,然后点击“添加”在点击“确实”即可。 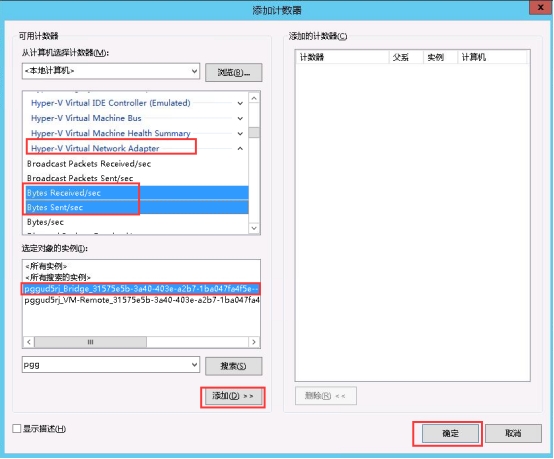 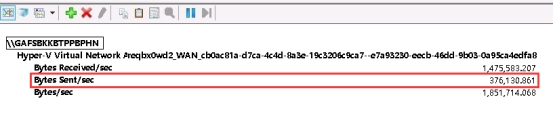 查看到Bytes Send/sec 速率为 376130 Bytes/sec 376130 / 1024 /1024 * 8 = 2.87 Mbps 该速率换算后带宽数值接近3Mbps 4.查看机器内socks套字节连接统计 查看有大量的tcp连接 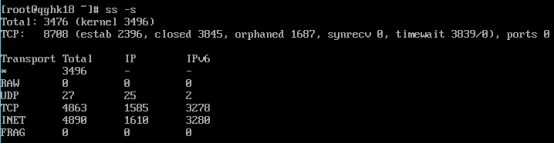 5.通过netstat命令查看统计实时连接情况 查看统计tcp连接数前10个的本地监听地址和端口,确定请求流量最多的本地监听地址和端口 netstat -antp | tail -n +3 | awk '{print $4}' | sed '/^$/d' | sort | uniq -c | sort -nr | head -10 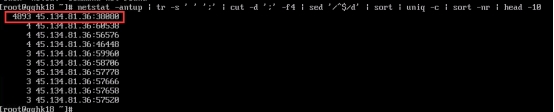 6.查看该端口对应的进程信息 netstat -tnulp | grep 38080 





































